Cómo he creado mi cerebro digital con IA
12 de febrero 2026
28 de agosto | Por Juan Merodio
Si vas en serio con agentes de IA en tu negocio, esto no va de “magia”: va de aritmética, arquitectura y control de costes variables. Aquí te dejo una guía clara, práctica y con números reales para que estimes y optimices el coste de tu agente en producción, con un enfoque 100% de negocio.

Resumen ejecutivo (para decidir en 60 segundos)
Con los supuestos de abajo (modelo GPT-5, 1.000 tokens de entrada y 500 de salida por llamada), cada llamada al LLM cuesta $0,00625.
Si tu agente hace 5 llamadas por mensaje, el mensaje cuesta $0,03125.
De ahí hacia arriba es pura aritmética (y un poco de ingeniería de prompts, orquestación y disciplina operativa).
Fórmula rápida:
Coste por mensaje = nº de llamadas LLM × $0,00625
Coste diario = mensajes/día × coste por mensaje
Coste mensual ≈ coste diario × 31 (conservador)
Puedes ajustar tus números, pero aquí trabajamos con estos supuestos para hablar el mismo idioma.
Modelo: GPT-5
(podrías abaratar con GPT-5 mini para pasos rutinarios o encarecer con modelos de razonamiento tipo o1-pro en tareas “A+”.)
Precios unitarios (los que compartiste):
Entrada: $0,00125 / 1.000 tokens
Salida: $0,01 / 1.000 tokens
Carga por llamada (típica en un agente bien afinado):
1.000 tokens in → $0,00125
500 tokens out → $0,00500
Total por llamada → $0,00625
Llamadas por mensaje: depende de tu diseño (orquestación, herramientas, RAG, validaciones, reintentos). Aquí comparo 1, 3 y 5.
Coste por mensaje = nº LLMs × $0,00625
Ejemplos simples:
1 llamada → $0,00625 por mensaje
3 llamadas → $0,01875 por mensaje
5 llamadas → $0,03125 por mensaje
Ejemplos reales (con tus cifras):
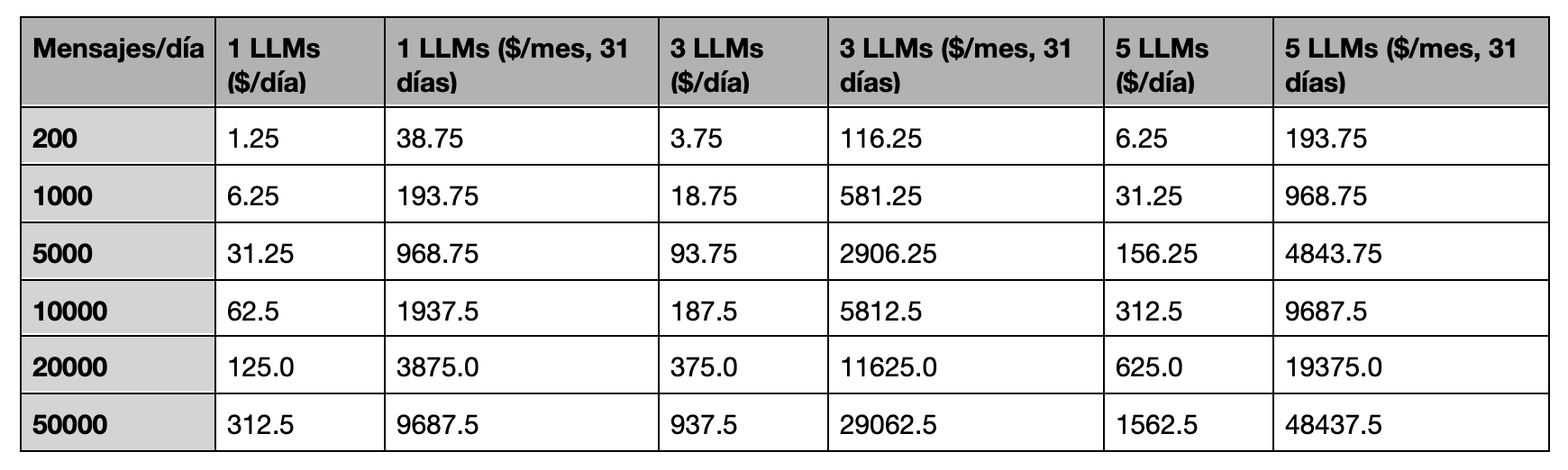
200 mensajes/día, 5 LLMs → $0,03125 por mensaje → $6,25/día → $193,75/mes
1.000 mensajes/día, 5 LLMs → $31,25/día → $968,75/mes
Supuestos: $0,00625 por llamada LLM, 31 días/mes.
Porque en producción pasan cosas:
Sub-agentes que se disparan según el caso.
Reintentos cuando un paso falla o la respuesta no pasa validaciones.
Herramientas externas (RAG, extracción, cálculo, clasificaciones) que añaden llamadas.
Si fijas el pipeline (por ejemplo, siempre 3 llamadas), el coste escala lineal. Si tu pipeline ramifica y aumenta el nº efectivo de llamadas por mensaje, el coste se dispara. La clave es medir y gobernar.
Tip: si un 10% de los mensajes exige 1 llamada extra, tu nº efectivo de llamadas por mensaje no es 3, es 3,1. Y el coste sube un 3,33% sin que te des cuenta.
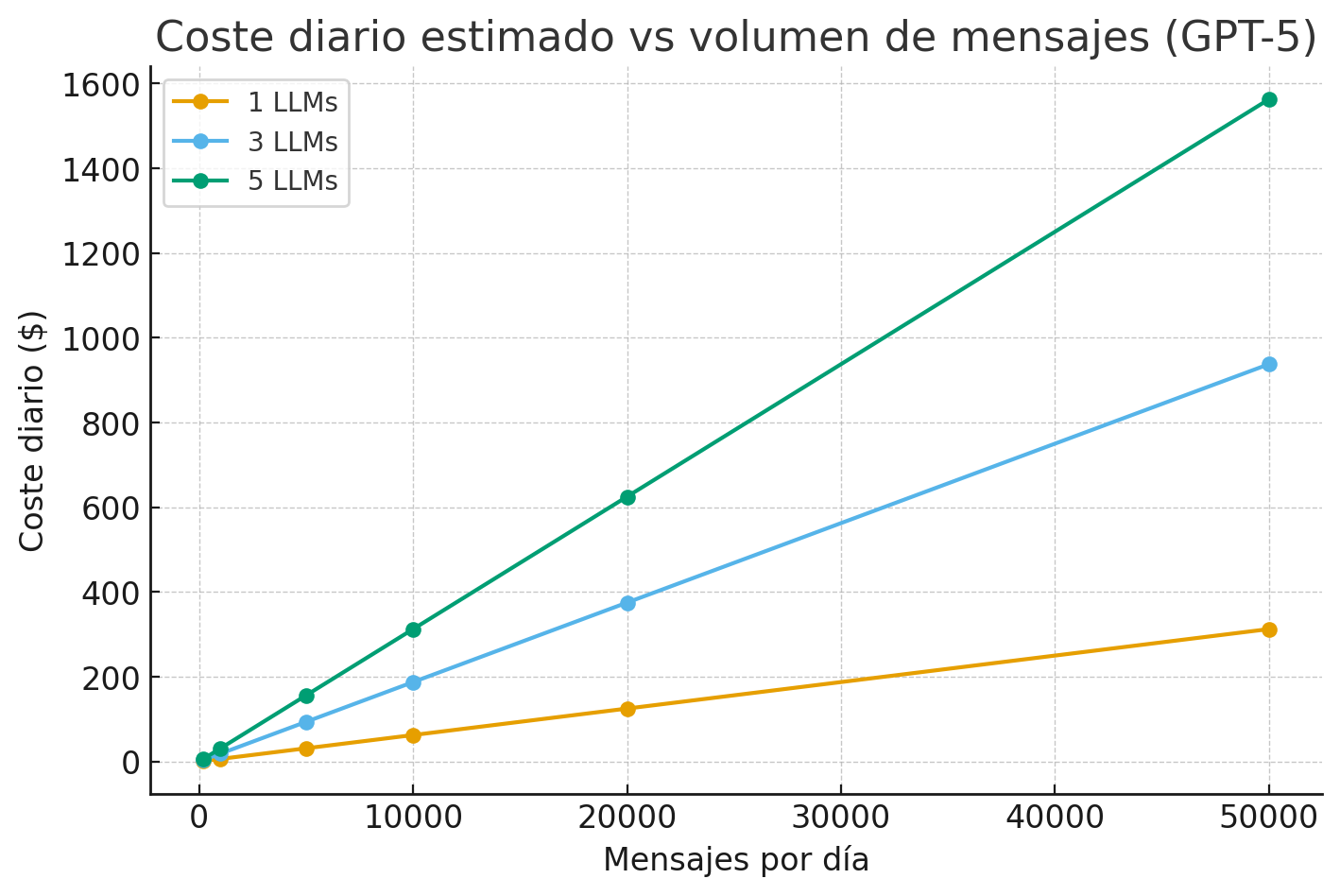
Con 50.000 mensajes/día (para ver el “big picture”):
1 LLM: 50.000 × $0,00625 = $312,50/día
3 LLMs: 50.000 × 3 × $0,00625 = $937,50/día
5 LLMs: 50.000 × 5 × $0,00625 = $1.562,50/día
Si buscas un coste cercano a $1.200/día, corresponde a ~4 llamadas por mensaje (≈ $1.250/día).
Con los precios dados:
Coste por llamada =
(Entrada_tokens / 1.000) × $0,00125 + (Salida_tokens / 1.000) × $0,01
Si mantienes 1.000 in y cambias out:
200 out → $0,00125 + $0,00200 = $0,00325
500 out → $0,00125 + $0,00500 = $0,00625
800 out → $0,00125 + $0,00800 = $0,00925
Reducir 300 tokens de salida te recorta un 48% el coste por llamada en este escenario. Por eso el control de verbosidad es oro.
Reduce tokens de salida
Respuestas concisas por defecto, con detalles on-demand (el usuario pide ampliar secciones).
Plantillas con bullet points y límites duros de longitud.
Compresión de contexto en RAG
Chunking adecuado (200–400 tokens por chunk suele funcionar bien para QA factual).
Resúmenes intermedios y reranking para enviar poco y relevante.
Caching agresivo
Embeddings y contexto estático cacheados.
Instrucciones del sistema y políticas en caché (o referenciadas por ID si tu orquestador lo soporta).
Cachea respuestas de FAQs muy repetidas.
Model-mixing inteligente
Usa GPT-5 mini (o un modelo más barato) para enrutado, clasificación y pasos rutinarios.
Reserva GPT-5 o un modelo de razonamiento para pasos críticos.
Guardrails y límites de reintentos
Máximo N reintentos por paso.
Short-circuit si no hay suficiente confianza.
Batching y colas
Agrupa tareas no urgentes fuera de horas pico.
Evita picos de coste y latencia que te hacen sobredimensionar.
Observabilidad de costes y tokens
Mide tokens in/out por paso, nº de llamadas por mensaje, ratio de reintentos.
Alertas cuando un flujo se “desmadra”.
Prompts “delgados” y estables
Evita concatenar histórico infinito.
Referencias compactas (IDs, resúmenes, plantillas).
Cierre temprana
Si el usuario ya tiene lo esencial, no fuerces pasos extra (por ejemplo, evitar un “resumen final” si no aporta).
A/B continuo
Evalúa variantes de pipeline y prompts con métricas de negocio (resolución, CSAT, coste por resolución).
Coste por mensaje (CPP): $/msg
Coste por resolución (CPR): $/conversación resuelta
Llamadas LLM por mensaje (promedio y p95)
Tokens in/out por llamada (promedio y p95)
Ratio de reintentos y fallos de herramienta
Latencia (p50/p95) y SLA
Deflection rate (porcentaje de casos resueltos sin pasar a humano)
CSAT/NPS y First Contact Resolution (FCR)
Meta sana: bajar CPR sin sacrificar FCR y CSAT. Si bajas coste pero sube escalado a humano, tu ahorro es ficticio.
No medir el nº real de llamadas por mensaje. El plan dice “3”, pero en logs salen “4,2”.
Respuestas prolijas sin control de longitud.
RAG mal afinado que mete 5–10 chunks innecesarios.
Reintentos silenciosos al 100% por validaciones demasiado estrictas.
No cachear partes estables.
Usar siempre el modelo caro por comodidad.
No cerrar la conversación cuando ya hay resolución.
Coste mensual ≈ (mensajes/día) × (nº LLMs por mensaje) × 0,00625 × 31
Ejemplo: 8.000 mensajes/día, 3 LLMs →
8.000 × 3 × 0,00625 × 31 = $4.650/mes (aprox.)
Definir el “happy path” de negocio
¿Qué es una resolución? ¿Qué pasos mínimos necesita? Define el pipeline estándar con el menor nº de llamadas.
Diseñar “ramas” solo para excepciones
Validaciones, herramientas y escalados se disparan condicionalmente con umbrales claros.
Elegir el stack y el model-mixing
Enrutado/clasificación con modelo ligero.
Razonamiento/creatividad con GPT-5 (solo cuando aporte).
Construir prompts y plantillas compactas
Tokens out limitados.
Contexto RAG mínimo y relevante.
Meter observabilidad desde el día 1
Logging de tokens, llamadas, reintentos y coste por paso.
Alertas de deriva (cuando un paso se infla).
A/B y hardening
Experimentos controlados para bajar coste manteniendo calidad.
Lista de regresiones evitadas (test suite).
Operativa y gobierno
Presupuestos, límites por tenant, mecanismos de corte si se sobrepasa el umbral.
Son ilustrativos para que veas números y decisiones. No reflejan sus datos internos reales.
Volumen: 8.000 mensajes/día (devoluciones, estado de pedido, cambios de talla).
Pipeline:
Clasificación (LLM 1, ligero)
RAG sobre políticas de devolución (LLM 2)
Respuesta final (LLM 3)
Coste: 8.000 × 3 × $0,00625 × 31 ≈ $4.650/mes
Optimización: respuestas breves con botones “ampliar”, cacheo de FAQs y plantillas de estado de pedido.
Volumen: 12.000 mensajes/día.
Pipeline (más complejo):
Clasificación y verificación de identidad
Cálculo de penalizaciones y disponibilidad
Respuesta + confirmación de cambio
→ 5 llamadas promedio (incluye herramienta y validación)
Coste: 12.000 × 5 × $0,00625 = $375/día → $11.625/mes
Optimización: compresión de contexto de tarifas, límites de reintento, y “cierre temprano” si el cliente acepta una de las 2 opciones pre-calculadas.
Volumen: 3.000 mensajes/día.
Pipeline:
Recuperar políticas internas por RAG
Respuesta con referencias y trazabilidad
→ 1 llamada (modelo razonador solo si es caso complejo)
Coste: 3.000 × $0,00625 = $18,75/día → $581,25/mes
Optimización: cache de secciones estáticas, y escalado humano inmediato para consultas fuera de política (evita reintentos caros y riesgos).
Volumen: 50.000 mensajes/día.
Pipeline:
Clasificación (ligero)
Diagnóstico + RAG técnico
Respuesta + sugerencia de solución
Validación rápida (si la respuesta cumple requisitos)
→ ~4 llamadas por mensaje (promedio)
Coste: 50.000 × 4 × $0,00625 = $1.250/día → $38.750/mes
Optimización: árboles de decisión pre-generados para errores comunes y respuestas por secciones (el usuario expande lo que necesita).
Día 0–30 (MVP con costes bajo control)
Define happy path y casos de excepción.
Elige modelo ligero para enrutado y GPT-5 solo en pasos críticos.
Implementa logs de tokens y llamadas por paso.
Aplica límites de longitud a prompts y respuestas.
Construye un cuadro de mando con CPP, CPR, tokens y reintentos.
Día 31–60 (optimización y estabilidad)
Añade cache de contexto e instrucciones.
Ajusta chunking y reranking en RAG.
Introduce alertas cuando suba el nº de llamadas por mensaje.
Crea tests de regresión para prompts críticos.
Día 61–90 (escalado y gobierno)
Establece presupuestos por equipo/tenant.
Implementa cortes automáticos si se superan límites.
A/B de model-mixing y compresión para bajar CPR sin perder FCR.
Documenta un playbook de incidencias (qué hacer si el coste p95 se dispara).
1) “¿Y si cambio de modelo?”
Recalcula con su precio por 1.000 tokens. La fórmula es la misma. Usa modelos más baratos para pasos rutinarios y deja el caro solo donde marque la diferencia. Si un modelo alternativo cuesta 50% menos, tu coste por llamada baja la mitad (si mantienes los mismos tokens).
2) “¿Es mejor limitar tokens de entrada o de salida?”
Salida duele más en este escenario (cuesta $0,01/1.000 vs $0,00125/1.000 en entrada). Empieza por recortar tokens out con plantillas concisas y “ver más”.
3) “¿Cómo estimo el impacto de reintentos?”
Suma al nº planificado de llamadas la probabilidad de reintento por el nº medio de reintentos. Si planeas 3 llamadas y un 10% de casos hace 1 reintento extra, tu media es 3,1 llamadas.
4) “¿Qué pasa con el histórico de la conversación?”
El histórico largo encarece y diluye la relevancia. Usa resúmenes y trae solo los turnos imprescindibles (y cachea los inmutables).
5) “¿Cómo defino un buen KPI de coste?”
Mide Coste por Resolución (CPR). Es el que conecta directamente con impacto en negocio. Puedes permitir un mayor CPP si FCR sube y reduces escalados a humano (que suelen ser más caros).
La IA no es magia: es estructura + contexto + control de coste variable.
Diseña tu agente para lograr la resolución con el menor nº de llamadas útiles y tokens justos. Escala la potencia del modelo solo cuando la tarea lo exija. Mide, itera y activa alertas cuando el pipeline se desvíe.
Y recuerda: los números de esta guía están basados en GPT-5 con los precios y supuestos definidos aquí. Si optas por modelos más avanzados (p.ej., o1-pro) estas cifras se multiplican; si usas uno más básico (o un mix inteligente), pueden reducirse de forma notable.

Juan Merodio
Juan Merodio es conferenciante internacional y emprendedor en innovación, IA y negocio. Con más de 20 años creando y liderando empresas, ha impartido más de 1.000 conferencias en España, Estados Unidos, Japón y Latinoamérica. Fundador de TEKDI y autor de 16 libros. Pero si algo lo define no es su currículum, sino su capacidad para ver lo que viene… y construirlo antes que nadie.
Compartir >>
Categorías
Posts imprescindibles
Más Leídos

Cómo he creado mi cerebro digital con IA
12 de febrero 2026

Calcula el retorno real de la Inteligencia Artificial en la empresa
7 de febrero 2025

De 1 Idea al Millón: Cómo Transformar tu Vida Personal y Financiera
9 de octubre 2024